这篇文章是在 2026 年 4 月 26 日参加杭州 build 03 活动上我的演讲稿,主题是 Lody: 随时随地指挥你的 Agent 团队。

大家好,我是 leon7hao,之前在达摩院做视觉算法,3 年前创业在做 loro.dev 和现在的 lody.ai。

在主题开始之前,我需要花几分钟介绍一下 Loro。Loro 是一个高性能的 CRDTs 框架,解决的是多端同步和多人协作上数据冲突的问题。例如笔记场景,设计软件场景,我们同时编辑一份文档,可能离线可能并行,谁应该覆盖谁,谁的编辑应该在前谁在后,CRDTs 是一个算法专门用来解决分布式场景离线优先场景下的数据冲突自动合并,我们不保证强一致性,但保证最终一致性。
也就是这里的冲突解决可能不符合真实的意图,但是只要我们通过同步得到的操作集合是一样的,那么所有人看到的状态就是完全一样的。相较于当前常用的 OT 中心化的算法,我们是可以做到业务无关的,自带版本控制的,端到端加密的。我们的理念是本地优先,用户自己设备上的那份数据才是 truth of source,保障用户数据的所有权、控制权,同时享受互联网带来的协作的好处。
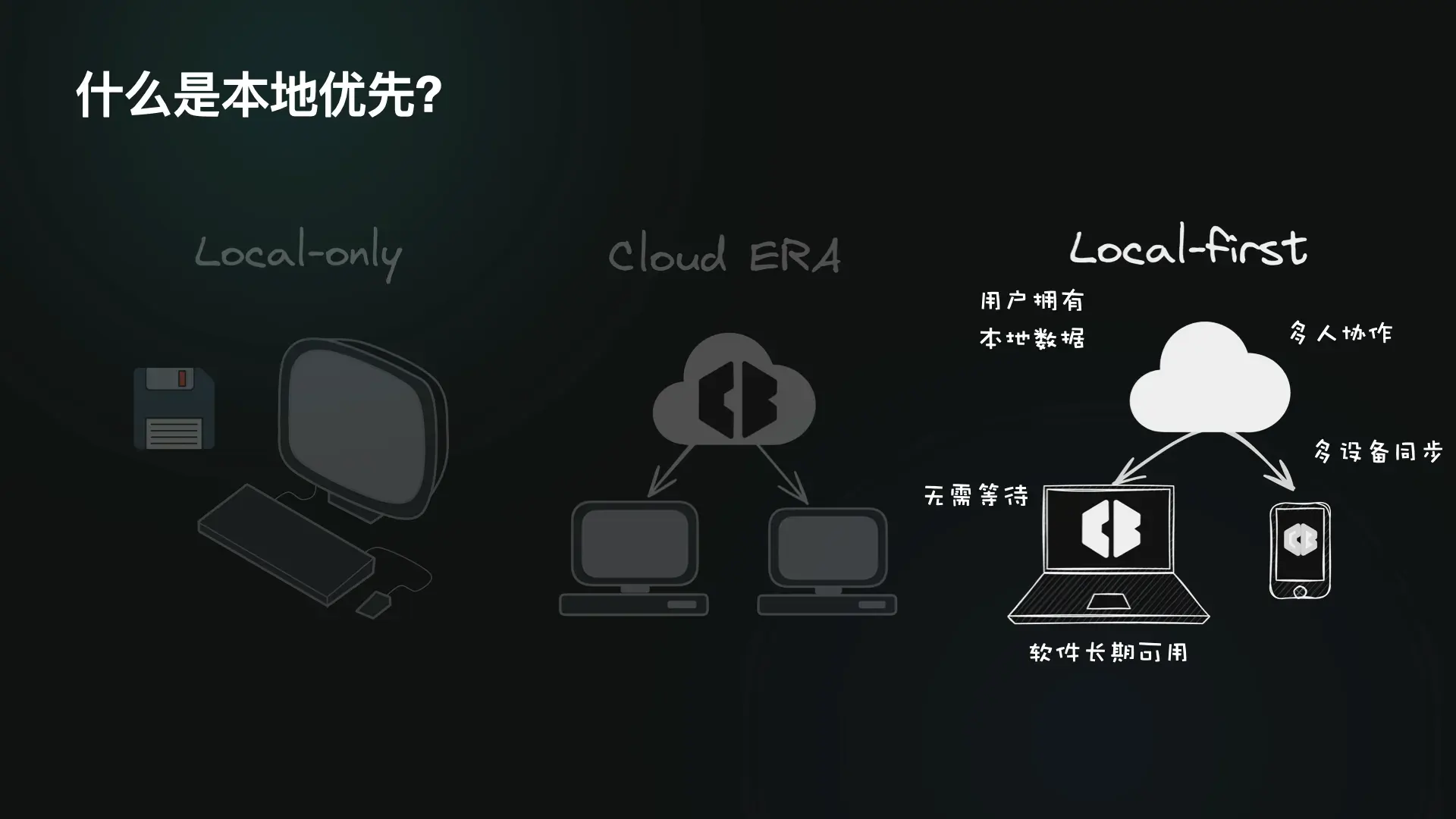
这部分可以直接看之前的分享,Local-first:不同以往的开发者体验,本地优先是一种新的软件开发范式,强调用户对数据的控制权和所有权,同时结合云的便利性进行协作。
我们围绕 loro 做了一些基建,正在去做对应的商业化,聚焦在同步领域的垂类部署服务。同时服务一些海外客户,但是他们用的好不好,对不对,我们没有体感。所以我们需要一个自己的场景来反馈,有多端同步需求的,和 AI 相关的,最好能够带来一些现金流的,我们必须每天自己在用的 dogfood,所以就是 coding,然后做了 Lody。

简单地讲就是在所有平台,桌面端、web 端,移动端来控制你自己的设备上的任意 code agent。
一开始是解决我们团队自己的问题,我们希望能够共享订阅,能够稳定 ip 不封号,有更好的并行开发能力,有更好的交互,能够看到对方在做什么。所以先从 web 入手,在服务器启动一个 CLI,服务器转发命令能够跑起来了。慢慢迭代,变成了现在的 lody 的样子。
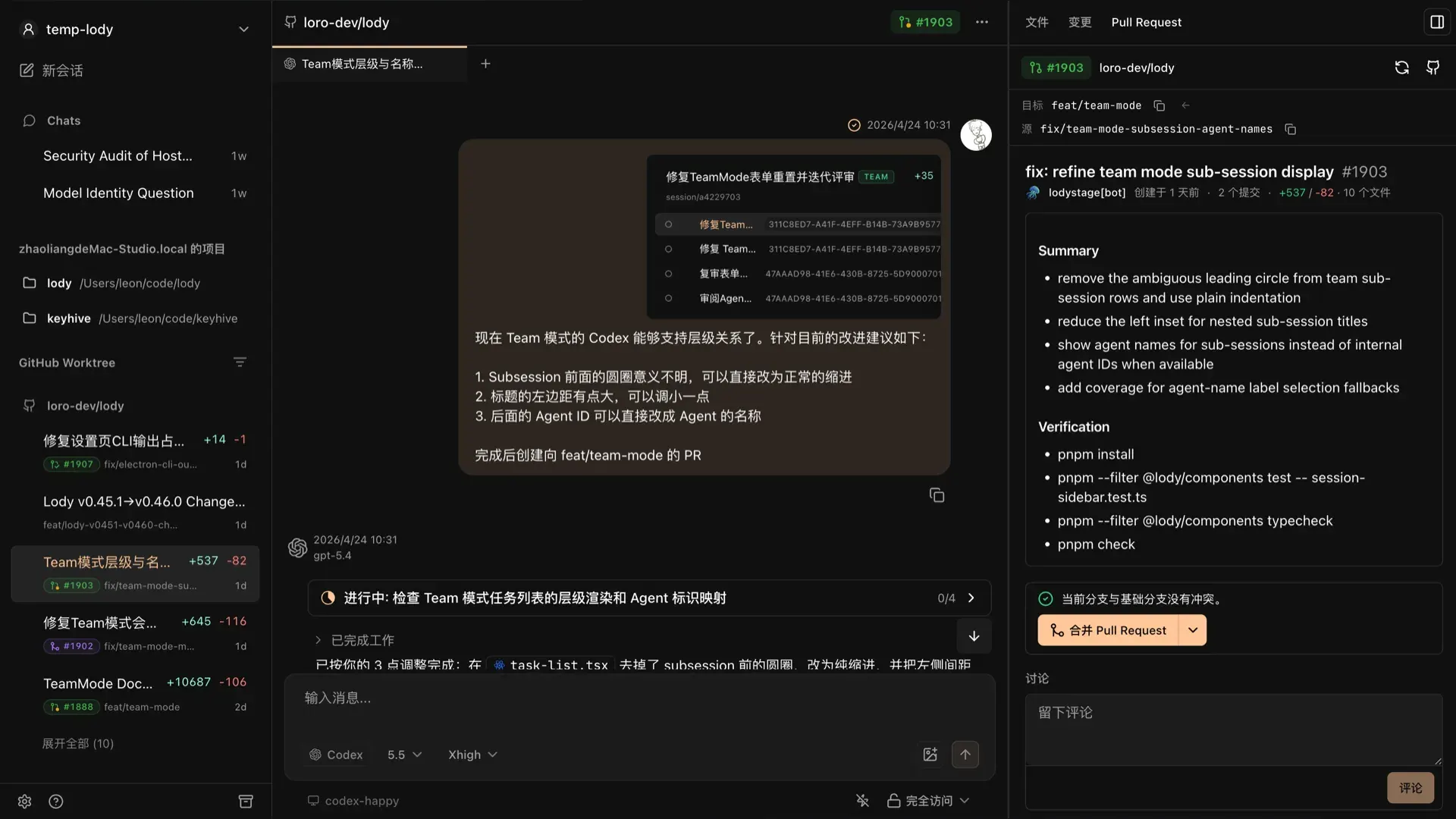
Lody 当前版本的样子,左侧是 sidebar,也就是你的工作区中的所有对话列表,支持 Chat,Local Project 和 GitHub WorkTree 三种对话类型。如果是 GitHub 集成的项目,会自动管理 worktree 进行并行开发,有 PR、分支的自动关联等。中间是对话区,使用友好的 GUI 的方式展示对话内容和 Agent 的执行过程。每轮对话之后都可以看到 Agent 的修改结果,你可以给 Agent 发送图像,它也可以给你返回图像。右侧是信息区,你可以查看文件,查看所有当前对话文件变更,查看对于的 PR 信息。还有更多 coding 场景下优化过的功能,可以查看官网的文档。
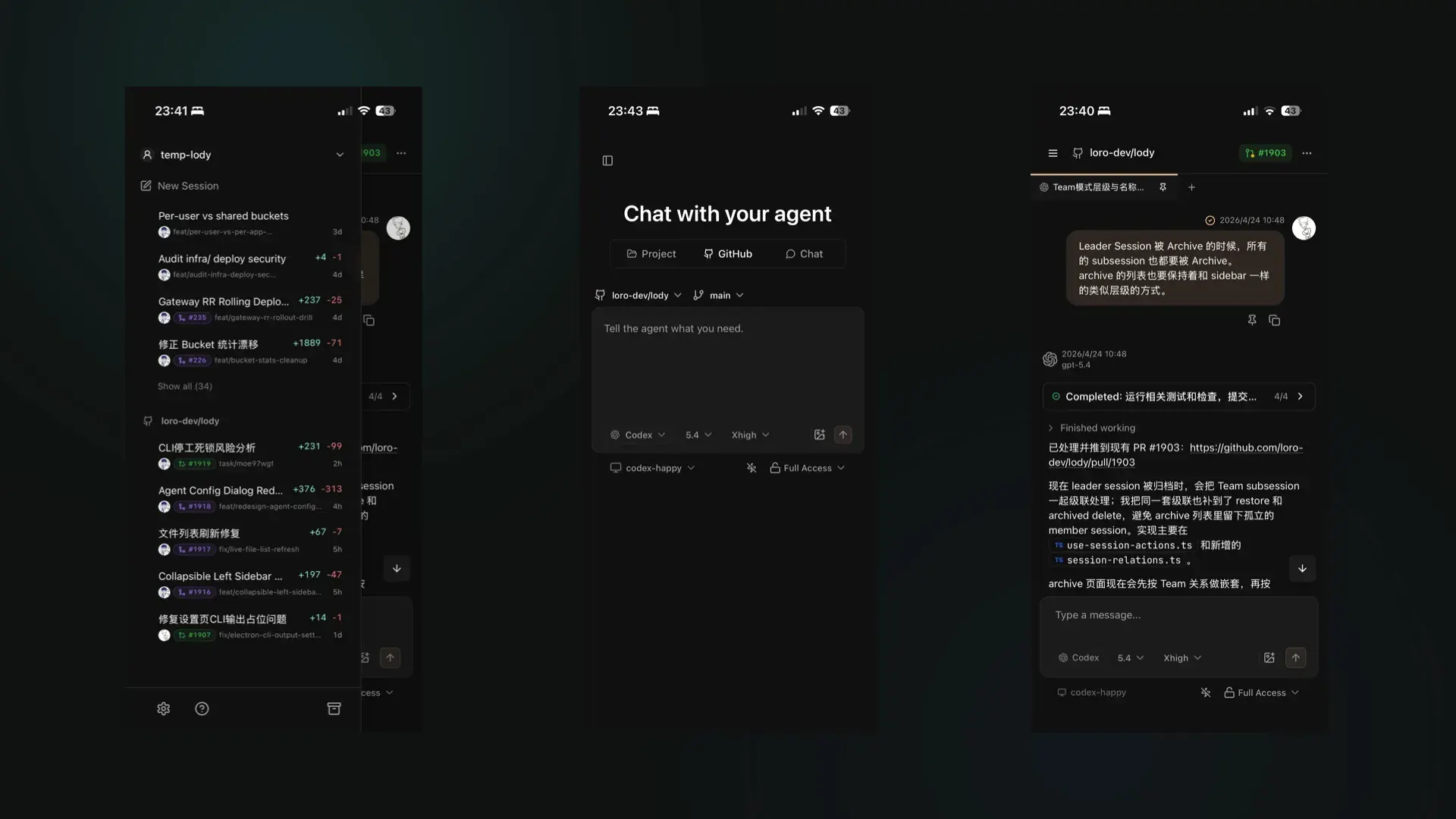
这是我们当前的移动端,基本是桌面端简单改了一下适合移动端的布局,之后会做更多 UI UX 上的优化,增加一些移动端特有的功能。之前提到的所有能力,移动端也都是支持的。这意味着,你可以出门只带个手机,就可以和在电脑前一样高效地指挥你的 Code Agent。

那么 Lody 解决了什么问题呢?

现在 code agent 大概十几分钟半个小时左右去完成一项任务,复杂一些的可能跑一个多小时。这时候也不能干等着,开一个新的对话窗口,但可能互相干扰,刚用 claude code 遇到过好几次,一个偷偷把另一个改的给还原了。所以需要磁盘文件上的隔离,就自然地要使用 worktree 这个东西,但这个东西挺难用,尤其是你需要本地测试的时候,涉及到环境变量,一些非 git 管理的文件。有一个主的工作目录,想切到下一个功能分支发现它在另一个 worktree 上,切不过来。
我们的方式是,worktree 只给 agent 用。lody 做好创建和回收,保持分支远端最新。人类就用本地自己的,想开发哪个切哪个,env 什么的就同一份,测试之前 git pull 一下。这样的工作流。测试出有什么问题就继续之前的对话,让 AI 继续修,本地再 pull 过来。反正我是这么用的。最大的好处就是,节省了你的注意力。完全不用考虑单工作区多窗口是否功能模块正交的问题,不用考虑刚刚的功能在哪个目录,worktree 怎么管理的问题。
很多人没有办法多个功能并行开发修复,我觉得很大的原因在于,关注了太多本应完全可以放手,不用进脑子的问题。

多端同步的好处是你不用担心我突然被打断了怎么办,随时出个门,坐个地铁遛个狗,完全不会有潜在的心理负担,拿起手机就走,打开之后和在电脑前是完全一样的状态,这样才是无缝的。除此以外,我们的同步是支持多人协作的,支持离线优先的、可以支持端到端加密的。如果你关注隐私,注重私有数据安全,但又想有这种无缝的体验,我真觉得除了我们之外不会有人会去做的。
我最爽的一次体验是在高铁上使用 lody,刚刚发出去指令就到了没有信号的地方,但因为执行侧我放在服务器上,等到有信号,一切都完成了,并且过程结果也都立刻同步好。如果不是 lody 我可能需要等十几分钟再发一次 continue。
控制端和执行端不在一侧还有另外的好处就是,除了信用卡因素之外,很难触发 claude 封号,即使是和其他人一起共享,因为 IP 固定,机器信息固定,cc 版本固定。
我们通过 ACP 对接了几乎所有的 code CLI,意味着你可以在一处同时使用和管理所有的模型。即使都是最好的模型,但是不同家的还是有不同的侧重点。即使是 GPT-5.5 前端设计的能力也还是打不过 Opus。在 lody 中这种交互就变得非常简单,点一下 tab 选另一个模型继续工作。一个是什么模型强我们用什么,所以对话会经常性地分散在各个应用或者 CLI 里。
另外一点,现在代码对于纯 vibe coding 来讲和编译之后的产物没什么区别了,这些对话才是真的源代码,而且是可以交互的源代码。我们团队中互相问某个功能怎么做的,怎么修复的,就直接发一个 lody 的链接自己去看。背景是什么,怎么修复的,细节是什么都在了。
虽然大家都在 vibe coding,但专业的开发者和纯 vibe coding 的朋友对结果的要求还是不一样的。很多人还是需要一种掌控感,我需要知道 AI 修改了哪些,每轮对话都可以查看 diff。GitHub 集成 PR 查看 CI 信息。

Lody 之后要解决什么问题。

我们之后计划去探索团队中如何更加 AI Native 开发软件的问题。不仅仅包括 coding,而是完整流程。也就是面向现在人和 agent 交互的两个问题,一个是 context 怎么给到 agent,另一个是 agent 效率变高超过人类的带宽之后怎么更进一步掌控的问题。

一开始想做 lody 的时候除了要解决我们当下使用 code CLI 时存在的问题之外。我们就已经锚定远期的目标是希望软件开发的完整流程都可以在 lody 中解决。lody 会成为 AI Natvie 的软件开发团队的 workspace。从立项开始,PRD的编写,技术调研,市场调研,设计稿,到开发实现都可以囊括在内。因为 coding agent 就是通用 agent。Lody 的角色就会是团队的 context 同步层。
现在的开发团队面临一个很现实的问题:代码在 Git 里,但真正的上下文散落在各处。notion 文档,figma 的设计,Slack 的讨论、Linear 的 issue、PR 的 review comments、还有各种和 AI 对话的内容。其他岗位我还不够熟悉,就拿写代码这个场景举例。
当一个新人接手某个模块,或者你三个月后回来看自己写的代码,经常需要花大量时间重建上下文——当时为什么这么做?考虑了哪些方案?有什么坑?或者是人类不再看代码,但你有没有遇到过开发和之前功能相关的部分时候,AI 会把已有的能力搞乱,或者经常发现已经出现过的问题经常又再次神奇地出现。这种时候往往是 AI 由于缺少足够的上下文进入了局部最优,从而错误地理解之前的代码。
Lody 的方向是把这些对话、决策过程、迭代历史都结构化地保存下来,并且和代码关联起来,这些都会变成可以被检索、被复用、被继承的知识。当你开一个新对话,AI 要修改相关的代码时,会自动地关联到已有的历史对话。
依托于我们使用 Loro CRDTs 作为底层的数据层,这些所有的 context 数据不仅仅是结构化的数据,还天然地能够带有版本控制,离线优先。并且这些我们将会以最开放的数据形式,例如文件,这种本地优先的形式保存到用户的本地。这相当于我们提供了面向 context 结构化数据的 git,团队中的成员可以查询到所有的历史记录,可以回滚到之前的任意一个版本,可以并行地进行工作,一切都会被优雅地合并。不用担心供应商锁定,你的数据永远是属于你自己的。

另外还有一个我们正在设计的能力,multi agent。
不同于 claude code codex 的 sub agent 或者 agent team。因为他们的基础模型是一样的,今年 1 月 亚马逊发表过一篇论文 《Rethinking the Value of Multi-Agent Workflow》他们实验下来认为同质的(homogeneous)模型进行角色分工来完成任务,本质上和单个模型串行地依次完成任务的效果差别不大。反而吃不到 cache 让成本更高(虽然感觉论文的数据不够 solid)。对于复杂的任务有一定的提升,认为提升来自的是拆分的 workflow 每个 agent 避免了上下文腐败,而不是因为 multi agent 本身。但 lody 是一个中立的平台,可以使用各类模型,使用异构的 multi agent 将任务拆分给最擅长这种任务的模型。比如 claude 擅长 UI,codex 擅长逻辑代码,小任务给国内的便宜模型。
除了性能效果会有提升之外,想去做 multi agent 对我更有影响的是 tibo 的一个推文。codex 的负责人 tibo 在 X 上表示 codex 在未来一年内任务完成的时间将会缩短一个数量级。

如果是真的,我也很相信这会是真的,我们就先假设这是模型和算力的基础能力进步带来的。那么我们现在一个基础任务会跑半个小时,其中测试之类的可能几分钟,那么缩短十倍的话,一个功能就会在五六分钟被完成,甚至把测试也跑完了。当前的所有交互模式就都不再适用了。时间是有限的,人们对于利用压榨时间的欲望是无限的。
如果 token 也变得便宜,你不可能想 像现在一样,发出去几个任务,挨个收菜的时候,慢慢测试,反正一个也得跑个几十分钟。一年后就变成你刚测试完一个,十个任务已经跑完了。所以把所有能够条件约束,能够被自动化验证的环节都交给 agent 会是必然的。也就是 multi agent 的形式。当前还是一个刚刚开始探索的领域,我们的构想是之后 harness 会更加完善,现在无法测试,验收标准不明晰的任务也将变得通过更加智能的 AI 从而可控可测。那么我们只需要通过和一个比如 lody agent 表达你的意图,它来理解你的意图,分析任务方向和难度,分配给擅长的合适对应子 agent。 他们会互相交流,便宜的模型会向最强的模型请求帮助,配合着把完整的周期自动化地走完。
当下看可能会觉得怎么可能,至少测试没有办法交给 AI,但 AI 真的是随着能力的增强,逐步窃取你的信任感,现在我们变得抛弃查看代码,之后就会抛弃手动测试,甚至 AI 变成了主动式地 push 你。我们只对最终产物做审查。
总结一下,Lody 和所有做 AI Agent 的目标大差不差,拥有 context 的前提下,你就拥有了最懂你们团队的 Agent Leader。
这个 Leader 知道你工作区的全部事情:哪些功能在开发、哪些 bug 在修复、哪些任务卡住了。它可以创建新的对话,把任务分配给专门的 coding agent,需要 review 的时候叫 review agent,需要搜索的时候派 search agent。它理解每个 agent 的能力边界,知道什么任务该分配给谁。更重要的是,它理解你的工作习惯和优先级。知道你更关注性能还是可维护性,知道你们团队的规范,它就是 workspace 最高效可靠的助手。
但我们的差异将会是在 Context 上,试想一下以本地优先的方式管理你所有的数据。所有的 context 都是无缝地在你多个设备之间,你和团队成员之间同步的,并且这个同步是端到端加密的,自带版本管理的,不会产生冲突的。我们将会以最开放的管理所有的 context,所以你不需要担心数据丢失,数据泄露,或者是供应商锁定的问题。
我相信所有人并不是不在意数据安全和隐私的,只不过之前没有更好的选择而已。我们希望通过 Lody,能够让每个人都能随时随地指挥自己的 Agent 团队,享受 AI 带来的效率提升,同时又不失对数据的控制权和安全感。
谢谢大家!